微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
在深度学习的发展历程中,注意力机制可以说是最具革命性的创新之一。特别是自注意力机制(Self-Attention),它不仅彻底改变了自然语言处理领域,更是Transformer架构的核心组件,催生了GPT、BERT等划时代的模型。 但什么是自注意力?为什么它如此强大?本文将从最基础的概念开始,逐步深入到数学原理和实现细节,帮你彻底理解这个改变AI世界的机制。
添加图片注释,不超过 140 字(可选)
一、直觉理解自注意力 (1)从人类阅读说起 想象你正在阅读这样一个句子 "那只在花园里追逐蝴蝶的小猫突然停下了脚步。" 当你读到"停下了脚步"时,你的大脑会自动关联到前面的"小猫",而不是"蝴蝶"或"花园"。这种能力让你理解是"小猫"在停下脚步,而不是其他事物。 这就是注意力的本质:在处理当前信息时,有选择性地关注相关的历史信息。
添加图片注释,不超过 140 字(可选)
(2)传统RNN的局限性 在自注意力出现之前,处理序列数据主要依靠RNN(循环神经网络)。然而,RNN存在三个根本性的技术局限。 1. 无法并行计算 RNN必须按时间步顺序处理,当前步骤依赖前一步的结果。
输入: [我, 爱, 吃, 苹果] 这种串行特性无法利用GPU的并行优势,训练速度受限。 2. 长距离依赖衰减 随着序列增长,早期信息在传递过程中逐渐丢失。
"那个穿红衣服的女孩昨天在图书馆里看的书很精彩" 实验数据显示,RNN在200词以上序列中,对开始位置信息的保留率仅为20%。 3. 梯度传播病理 反向传播时梯度需要经过多个时间步,容易出现梯度消失(梯度变得极小,无法更新参数)和梯度爆炸(梯度变得极大,破坏训练稳定性)。 # 梯度传播链 梯度问题使得RNN难以处理长文本,训练效率低下。 (3)自注意力的核心思想 自注意力机制的革命性在于,让序列中的每个位置都能直接关注到其他所有位置。
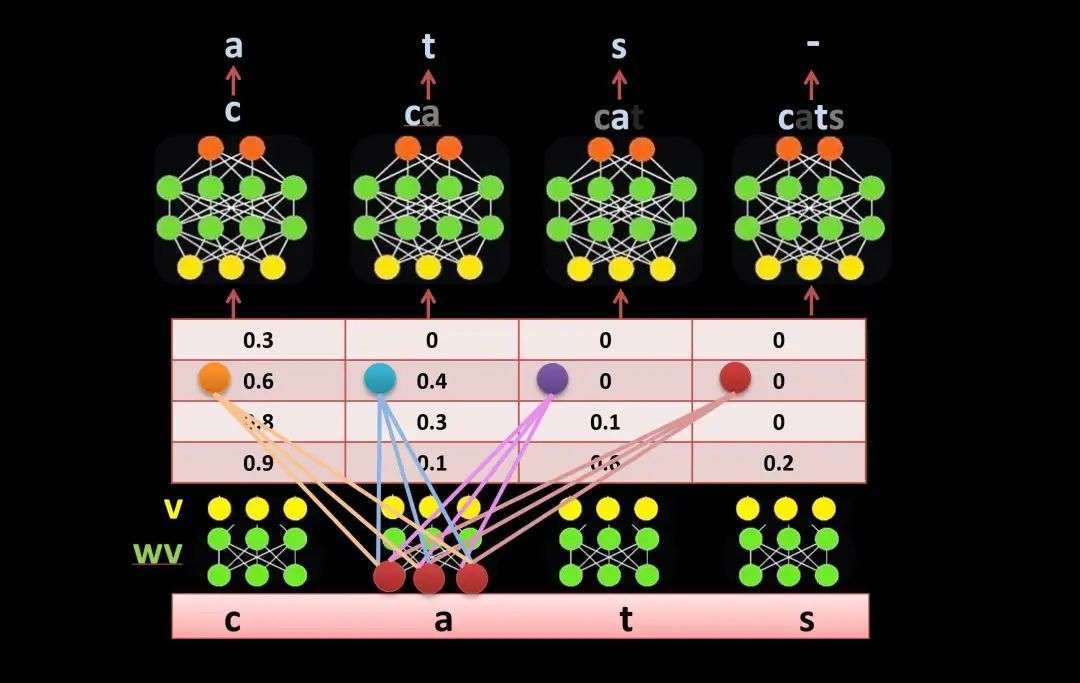
添加图片注释,不超过 140 字(可选)
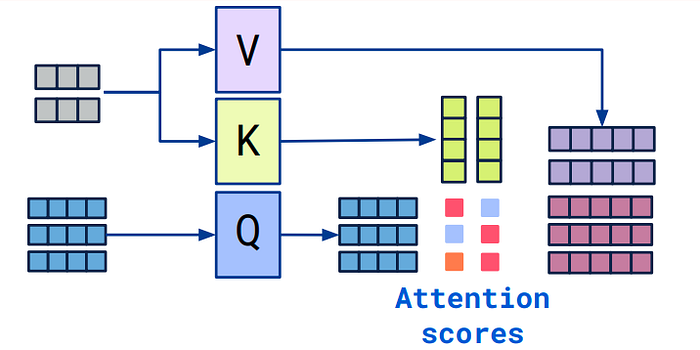
输入: [我, 爱, 吃, 苹果] 1. 并行计算 所有位置可以同时处理,充分利用GPU的并行计算能力,训练速度比传统序列模型快10-100倍。 # 自注意力:一次性计算所有位置的交互 2. 直接连接 任意两个位置都能直接交互,路径长度恒定为1,避免信息在传递过程中的衰减,能够准确捕捉长距离的语法和语义关系。 词1 ←→ 词100 (直接连接) 3. 动态权重 根据内容相似度动态计算注意力权重,重要信息自动获得更高关注度。 # 示例:"小猫在花园里追蝴蝶,然后它停下了" 二、自注意力的数学原理(1)核心概念:Query, Key, Value 自注意力的核心是三个矩阵:Query (Q)、Key (K)、Value (V)。
添加图片注释,不超过 140 字(可选)
-
Query:你在问"我需要什么信息?"
-
Key:每个位置的"标签"或"索引",用来判断是否匹配Query的需求
-
Value:每个位置的实际信息内容,当Key匹配时就提取这些内容
例如你在图书馆查资料,具体Query、Key、Value的含义。
-
Query:你的检索词(比如"深度学习")
-
Key:每本书的标题和索引
-
Value:书的实际内容
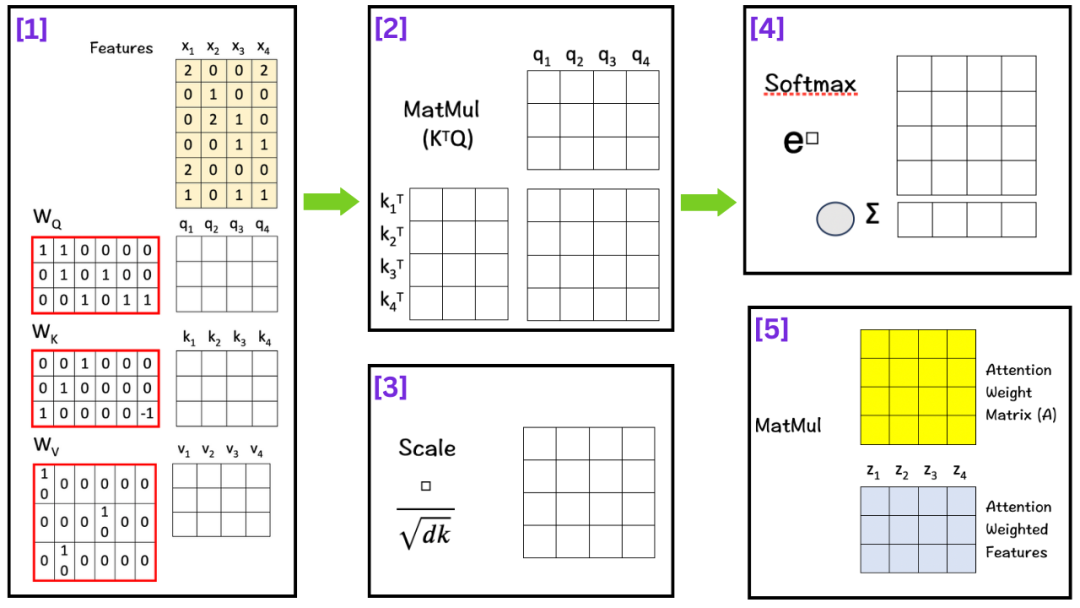
你会根据检索词与书籍标题的匹配度,决定重点阅读哪些书的内容。 (2)数学公式详解 自注意力的核心公式:Attention(Q,K,V) = softmax(QK^T/√d_k)V
添加图片注释,不超过 140 字(可选)
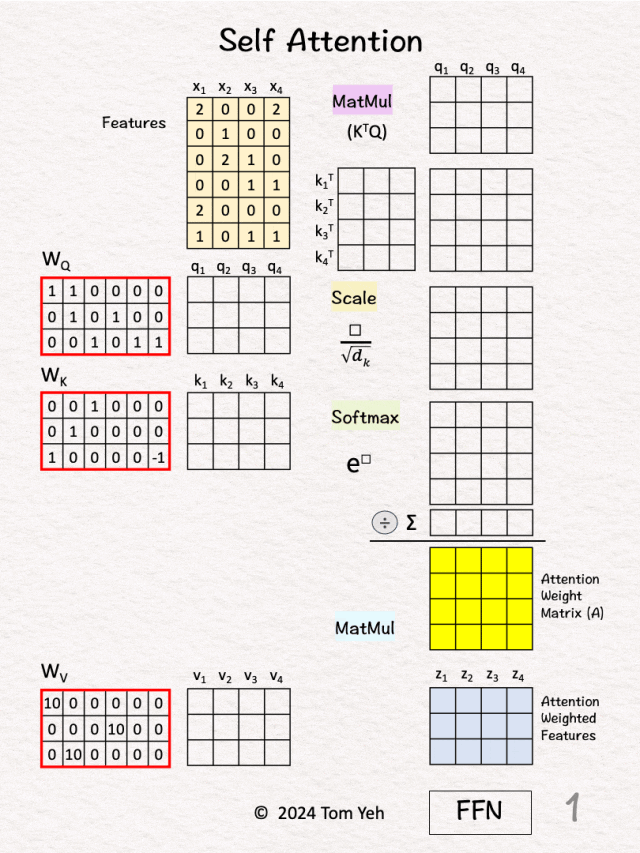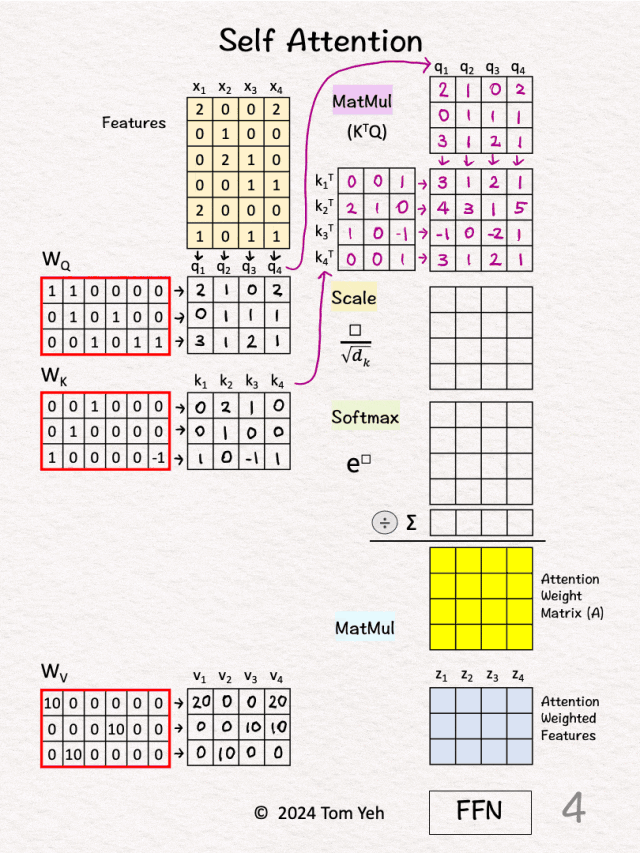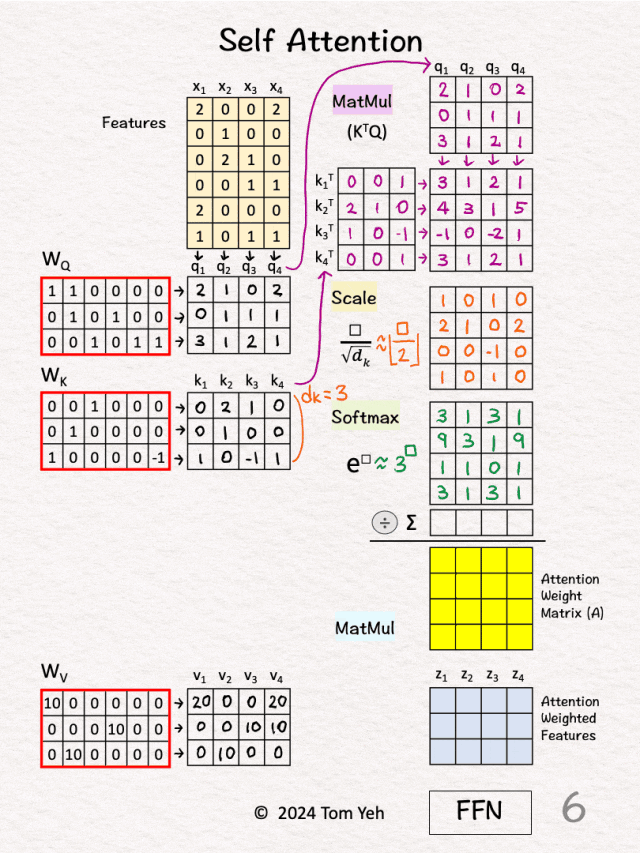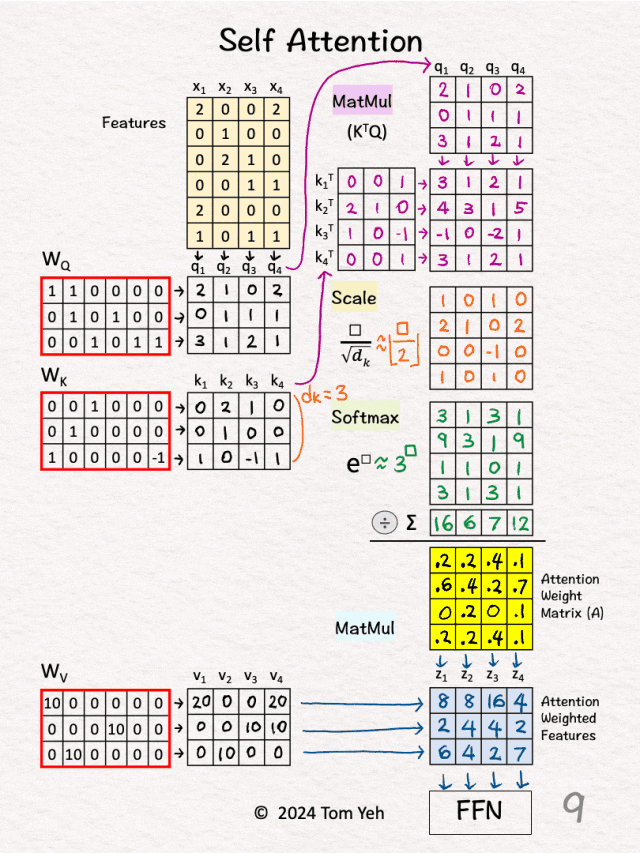
步骤1:计算注意力分数 这一步计算的是每个Query与每个Key的相似度。 Score = QK^T步骤2:缩放处理 为什么要除以√d_k?当d_k很大时,QK^T的值会很大,很大的值经过softmax后会产生极端分布,缩放确保softmax的输入在合理范围内。 Scaled_Score = Score / √d_k步骤3:Softmax归一化 softmax确保所有权重都是正数,使得每行权重和为1,从而形成概率分布。 Attention_Weight = softmax(Scaled_Score)步骤4:加权求和 根据注意力权重对Value进行加权平均。 Output = Attention_Weight × V(3)具体计算示例 假设我们有输入序列:"猫 坐在 垫子 上" 输入表示(简化为2维):
x1 =[1.0,0.5]# "猫"步骤1:生成Q, K, V
# 权重矩阵(简化)步骤2:计算注意力分数
Score = Q @ K.T步骤3:Softmax归一化 # 对每行进行softmax步骤4:输出计算
-
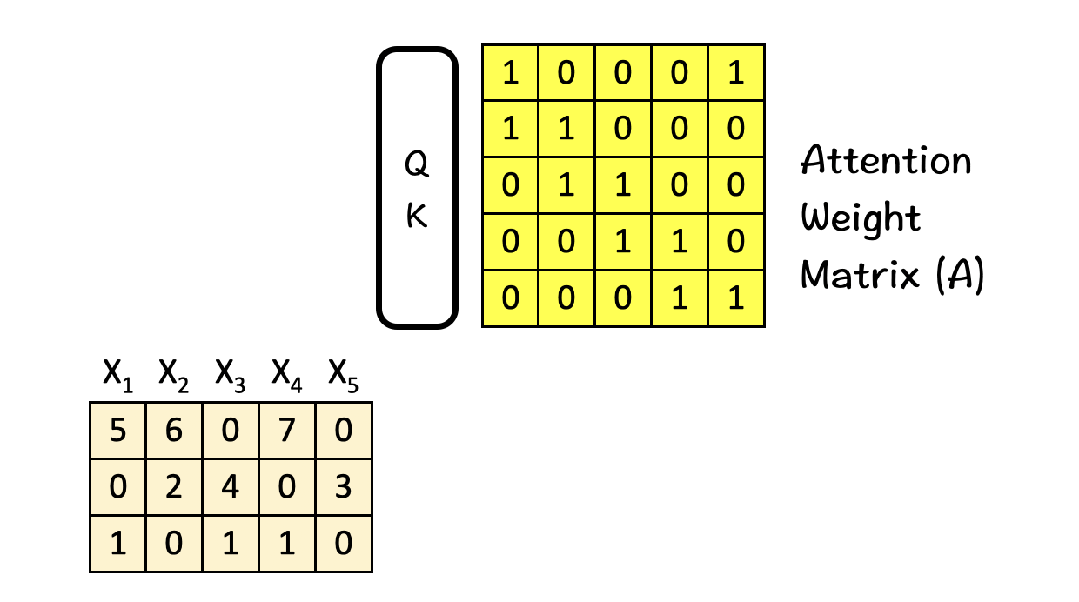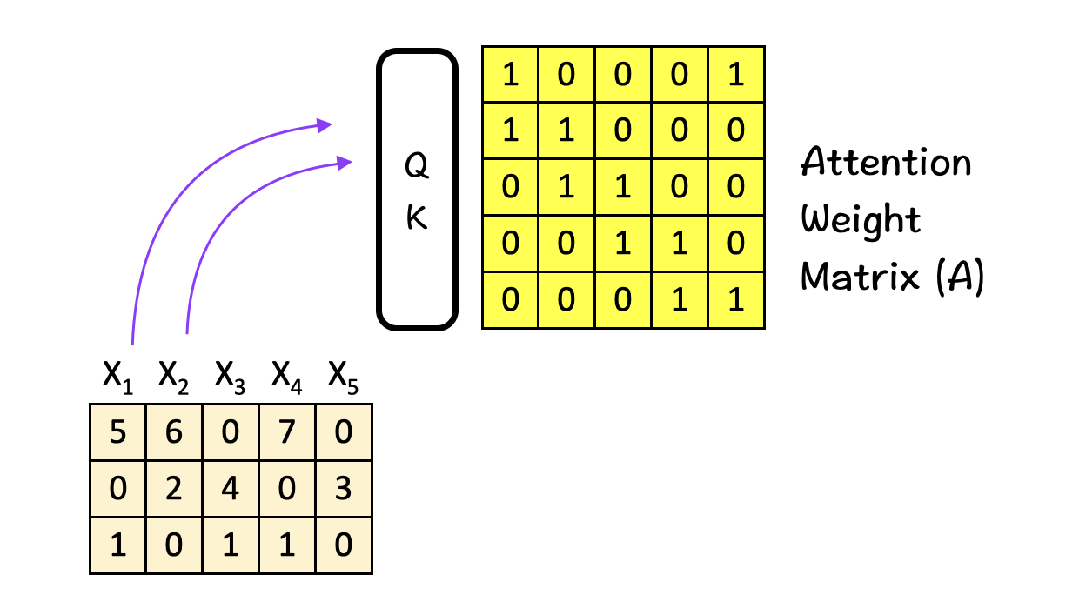
Output = Attention_Weight @ V(4)注意力矩阵的解读 注意力权重矩阵是一个 seq_len × seq_len 的矩阵,其中:行表示某个位置(Query),列表示关注的位置(Key),值表示关注程度。
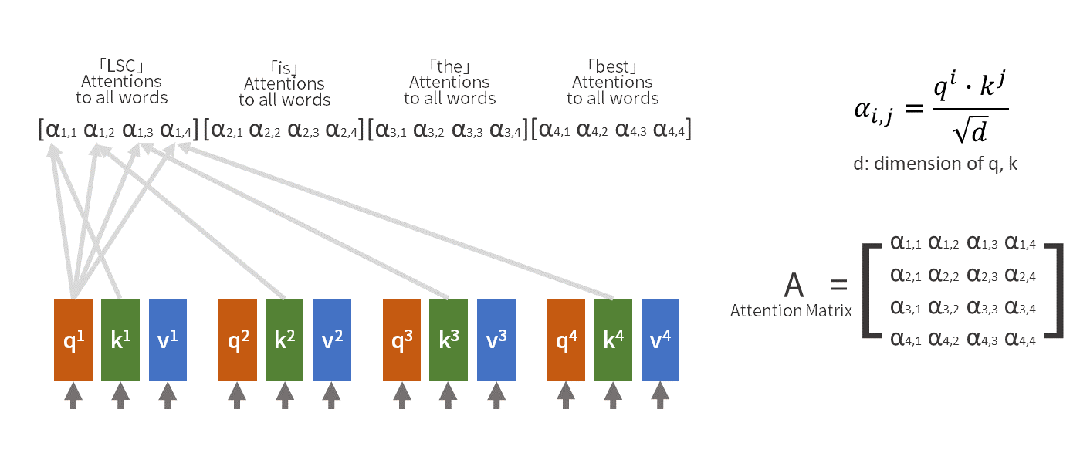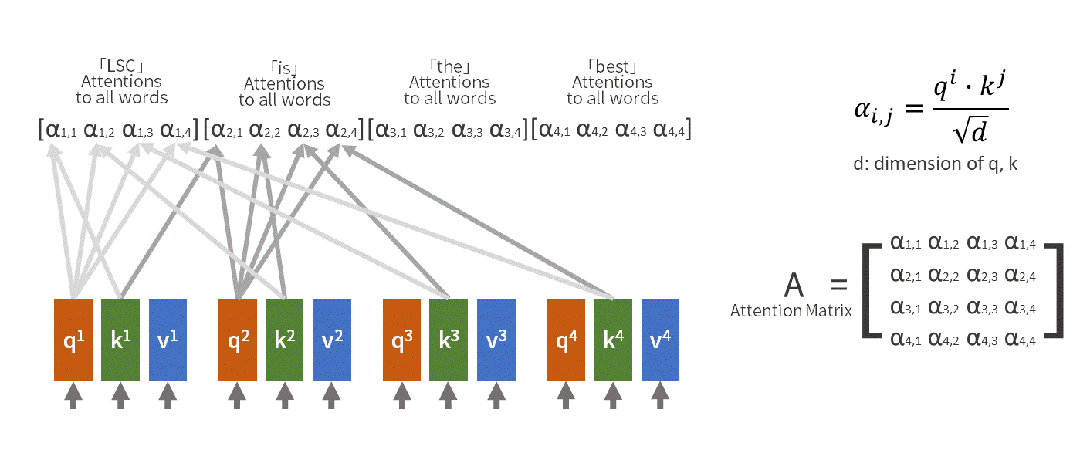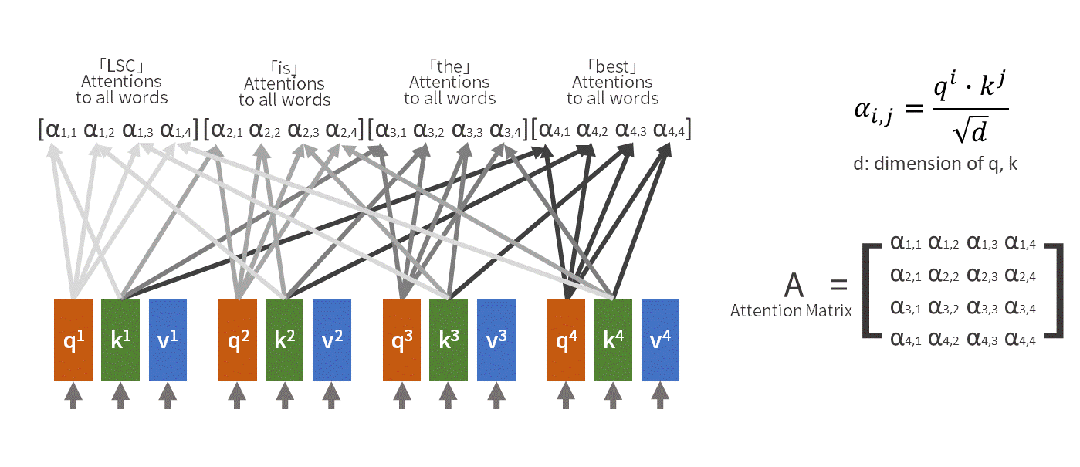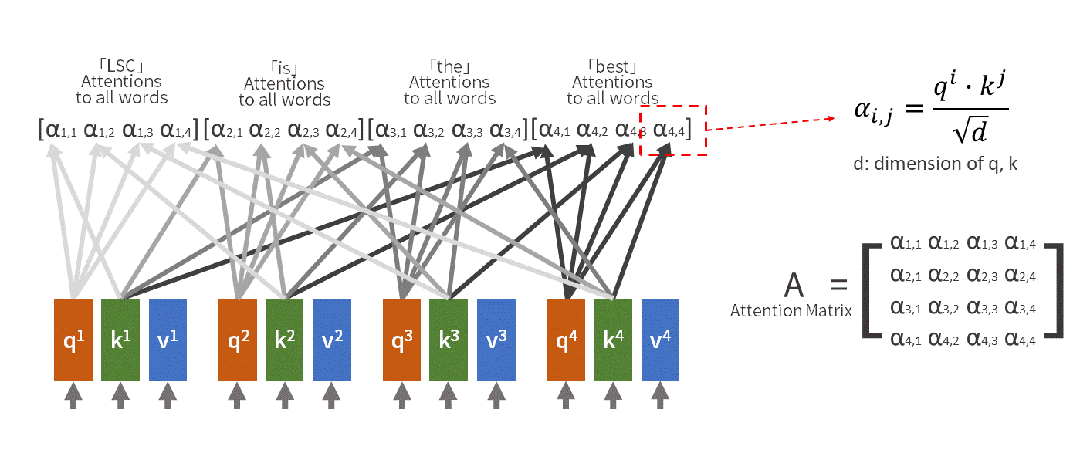
添加图片注释,不超过 140 字(可选)
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
https://mp.weixin.qq.com/s/HxtdK9G5VTMtxVSWHVYFQg