一、简介
(一)什么是 Git
Git 本质是分布式版本控制系统(DVCS),由Linus Torvalds为管理Linux内核开发而创建,主要用在软件代码版本管理
Git 可以代码共享、历史修改记录,方便代码管理追溯与回滚
(二)基本原理
四个工作区域(三个工作区域 + 远程仓库),如下图:
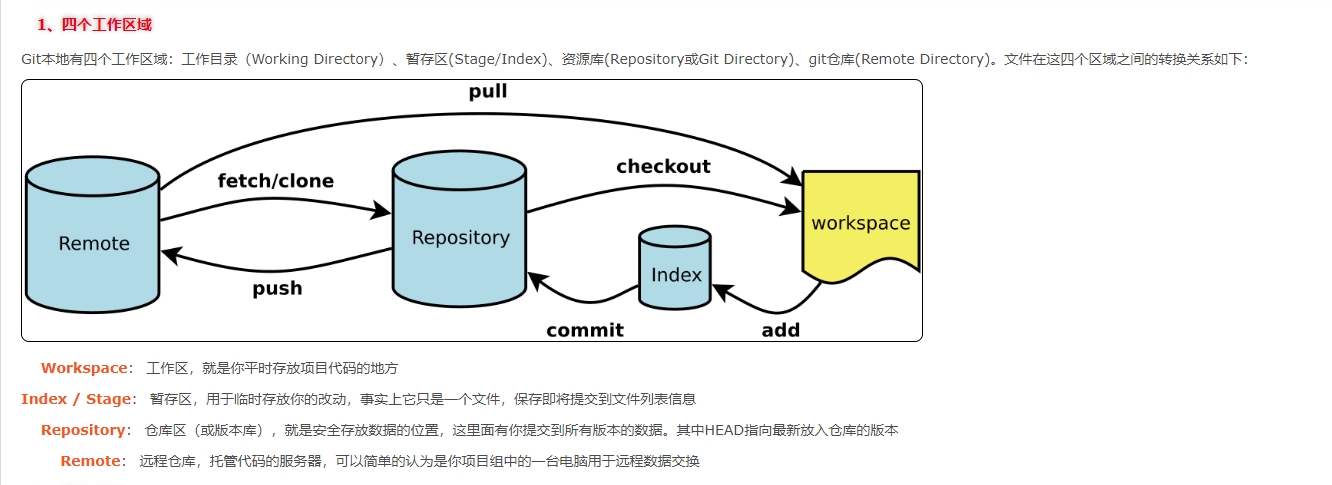
| 四个工作区域 | 说明 |
|---|---|
| workspace(工作区) | 代码目录(代码文件夹,不包含 .git 子文件夹) |
| index(暂存区/缓存区/Stage) | 存放临时改变(.git 目录下的 index 文件) |
| repository(本地仓库) | 这里存放的是本地仓库的历史修改版本,也就是 index 的内容进一步安全保存(.git/objects目录中) |
| remote(远程仓库) | 一个共享代码仓库,区别于repository(本地仓库),远程仓库是可共享的,其他人都可以看得到,本地仓库只有你自己可以看到 |
(三)基本工作流程
-
创建/拉取一个 Git 仓库,用于存储本地代码
方式一:直接创建仓库
# 创建一个目录 mkdir project# 初始化 git 管理,使用当前目录作为 Git 仓库 cd project && git init本质上就是在 project 目录下创建了 .git 子目录,git 就可以进行监控了
方式二:拉取远程仓库
git clone <远程仓库地址>常用,一般在工作的时,团队都有一个远程仓库,只需要拉取即可
-
修改代码,提交修改到 index 暂存区
使用 git add <文件....>提交修改
# 提交当前目录下所有的修改 git add .一般开发工具会将待提交 index 的修改识别为 绿色
-
提交 index 暂存区代码到 repository 本地仓库
使用 git commit -m <填写备注> 提交 index 的修改到本地仓库
git commit -m '修改1'一般开发工具会将需要提交本地仓库的修改识别为 蓝色
-
提交本地仓库代码到远程仓库(可供团队其他成员共享)
代码已经存在应用到了本地仓库,但是其他人是看不到的,还需要将代码提交到远程仓库才行
# 需要先 git pull 更新远程仓库代码到本地仓库(因为可能团队其他人也做了修改) git pull# 如果执行 git pull 出现冲突,则需要先解决冲突 # (就是你改的代码,其他人也改动了并且存在远程仓库,git 无法帮你做选择,需要你手动选择要保留谁的代码)# 处理完冲突,需要再将代码先提交到本地仓库(每次有代码改动都需要 git add && git commit 提交到本地仓库)# 提交代码到远程仓库 git push
(四)开发流程(工作版)
在前面讲的都是一些基本概念和基本的操作,但是实际工作还不太一样,这里给出我工作中常规的开发流程
首先,拉取团队的代码远程仓库
git pull <远程仓库地址>
基本上很少需要自己创建仓库的情况,都是拉取团队已经存在的远程仓库
此时默认的分支为 master
什么分支?顾名思义,和树一样,有主干和分支,一般正式环境上运行的为主干代码,其他分支代码为开发者开发中的开发代码
其次,接到开发需要,我们需要先创建一个开发分支
git checkout -b feature/new_func
checkout 表示 切换分支
-b 表示如果分支不存在,则自动创建
以上命令表示基于 master 分支创建了一个新分支 feature/new_func
此时分支 feature/new_func的代码和 master 一致,但是在分支feature/new_func 上修改代码不会影响 master分支,代码隔离
# 创建后分支是在本地仓库的,我们还需要推送到远程仓库(如果是多人协作的,也就是一个需求多人开发)
git push --set-upstream origin feature/new_fucntion
然后其他同事就可以拉取到你这个分支了
git pull && git checkout feature/new_fucntion
接着,你就只需要在 feature/new_fucntion 挥霍写代码了,写完自测完成后合并到测试环境,供测试人员进行测试验证
# 提交代码到本地仓库
git add . && git commit -m '我写个很牛的功能'# 注意一定要先更新本地仓库才能推送到远程仓库(因为其他人可能做了修改)
git pull# 解决冲突,如果有的话# 再推送到远程仓库
git push
在合入之前,需要先将 master 代码合并到当前分支
# 切换分支到正式环境,一般正式环境分支名称为 master/main,具体看团队定义
git checkout master # 如果本地不存在,则需要先执行 git pull# 此时位于 master 分支,注意一定要先更新远程仓库,因为现在的 master 分支是存在你的本地仓库的,不是最新的远程仓库代码
git pull # 切换到需求分支
git checkout feature/new_fucntion # 合并 master 代码
git merge master# 处理冲突# 推送到远程仓库
git push
为什么需要这个操作?master 代码一定是最新、最全、最安全的,test 分支必须包含 master分支代码,所以你的需要分支在合入 test之前,需要先更新,否则会出现,master 有的代码,你的分支没有,然后你又合入了 test,后续的操作就会造成代码丢失
需要将需求分支的所有 commit 打包成为一个 commit
执行 git log 你可以看到你在开发过程中每次提交的 git commit 信息,这些都是开发备注,一旦合并到master,在 master 分支就能看到这些 log,这不是必要的,也不方便管理,master 的 log 应该保持干净整洁(毕竟出了问题还要追溯是谁写的代码)、方便代码回滚
所以需要将这一些 log 打包成为一个 log,
方式有很多,我这里提供一个参考
# 更新本地仓库 master 代码(如果已经更新则忽略)
git chekcout master && git pull# 切换需求分支
git checkout feature/new_fucntion # 提取所有变更
git reset master# 此时所有修改的代码都在 index 暂存区,重新提交一次即可
git commit -m '这是一个新功能'git push -f # 需要加上 -f ,表示强制更新远程仓库# 再查看 log,会发现除了 master 本身就有的log 之外,只有一个 log 了,之前的开发log都没了
git log
git reset master 意思就是 feature/new_fucntion 和 master 分支的差异全部还原到 index 暂存区
也就是说 feature/new_fucntion 分支上你所有的修改都需要重新执行一次 commit,
合并到测试环境
# 切换分支到测试环境,一般测试环境分支名称为 develop/test,具体看团队定义
git checkout test # 如果本地不存在,则需要先执行 git pull# 此时位于 test 分支,注意一定要先更新远程仓库,因为现在的 test 分支是存在你的本地仓库的,不是最新的远程仓库代码
git pull # 合并需求分支到当前分支
git merge feature/new_fucntion # 解决冲突(如果有的话)# 提交合并代码到本地仓库(如果解决了冲突,没有冲突则跳过)
git add . && git commit -m 'merge'# 此时 feature/new_fucntion 代码就已经在 test 分支上了,只需要推送到远程仓库即可
git push # 代码合并完成,然后就是代码发布(也就是代码生效),每个团队的发布规则不同,具体看团队我这里是自动化的,也就是只要 test 分支代码发生变化,测试环境就会重新自动部署(比如 gitlab、jenkins等 CI/CD )
好了,到这里,你的需求已经开发完成了,就等测试人员测试验证即可,测试过程中如果有 bug,
就还是在分支 feature/new_fucntion 继续修改,然后重复上面合并的步骤即可
最后,测试验证通过,进行代码发布环节
在合入之前,需要先将 master 代码合并到当前分支
# 切换分支到正式环境,一般正式环境分支名称为 master/main,具体看团队定义
git checkout master # 如果本地不存在,则需要先执行 git pull# 此时位于 master 分支,注意一定要先更新远程仓库,因为现在的 master 分支是存在你的本地仓库的,不是最新的远程仓库代码
git pull # 切换到需求分支
git checkout feature/new_fucntion # 合并 master 代码
git merge master# 处理冲突# 推送到远程仓库
git push
为什么需要先合并 master ?feature/new_fucntion 是基于 master 分支切出来,在你开发的过程中,可能其他同事修改了 master 分支,也就是 master 分支可能存在 feature/new_fucntion 分支不存在的代码,或者修改的代码和你修改的代码存在冲突
当然你可以不做这个操作,但是你在 master 合并你的分支时就会出现冲突需要解决,会出现很混乱的提交记录,这在工作中是不允许的
需要将需求分支的所有 commit 打包成为一个 commit
执行 git log 你可以看到你在开发过程中每次提交的 git commit 信息,这些都是开发备注,一旦合并到master,在 master 分支就能看到这些 log,这不是必要的,也不方便管理,master 的 log 应该保持干净整洁(毕竟出了问题还要追溯是谁写的代码)、方便代码回滚
所以需要将这一些 log 打包成为一个 log,
方式有很多,我这里提供一个参考
# 更新本地仓库 master 代码(如果已经更新则忽略)
git chekcout master && git pull# 切换需求分支
git checkout feature/new_fucntion # 提取所有变更
git reset master# 此时所有修改的代码都在 index 暂存区,重新提交一次即可
git commit -m '这是一个新功能'git push -f # 需要加上 -f ,表示强制更新远程仓库# 再查看 log,会发现除了 master 本身就有的log 之外,只有一个 log 了,之前的开发log都没了
git log
git reset master 意思就是 feature/new_fucntion 和 master 分支的差异全部还原到 index 暂存区
也就是说 feature/new_fucntion 分支上你所有的修改都需要重新执行一次 commit,
然后就可以合并代码到 master 了
和发布测试环境基本一致,就是
发布测试环境是将你的代码合并到 test 分支,
发布测试环境是将你的代码合并到 master 分支,
仅此而已
⚠️⚠️⚠️:发布正式环境理论上是这样子,但是一般工作中 master 分支是受保护的,所以在合入 master 分支的步骤是不同的,
具体需要看团队
常见的分支名称及定义(业内):
| 分支名称 | 含义 |
|---|---|
| master | 最新、最全、最可靠、正式环境运行的代码,有的名称是 main,一般是团队自己定义的名称 |
| release | 已验证,可以发布的版本分支,一般用作灰度发布(少部分用户可见),不一定有,看团队 |
| develop/test | 测试分支,一般都会有一个测试环境(正式环境也就是面向用户可见的),测试环境是团队用作代码验证测试的,一般开发者讲需求开发测试后合并到测试环境供测试人员进行测试,没问题才能正式上线 |
| feature/xxx | 需求分支,开发者接到需要,会基于 master 分支切出一个需要分支进行代码开发,然后代码经过测试验证之后再合并到 master 分支正式上线,注意:名称规则不一样,具体由团队定义 |
| hotfix/xxx | 修复线上 bug,注意:名称规则不一样,具体由团队定义 |
二、如何安装 Git
请移步文章 如何安装 Git
三、Git 和 SVN 的区别
| 特性 | Git | SVN |
|---|---|---|
| 架构模型 | 分布式 有本地仓库和远程仓库的概念,离线状态下,本地仓库就是一个版本控制系统 |
集中式 只有远程仓库才有版本控制 |
| 本地完整性 | 完整历史记录在本地 | 工作副本仅含文件,不包含历史记录 |
| 离线操作 | 提交、分支、查看历史无需联网 | 几乎所有操作都需要连接中央服务器 |
| 分支模型 | 轻量级分支(瞬间创建) | 重量级分支(服务器端副本操作) |
| 提交方式 | 先提交到本地仓库 ---> push 到远程仓库 | 直接提交到远程仓库 |
| 版本号不同 | SHA-1哈希值 | 全局递增整数组件号 |
| 学习曲线 | 较陡峭(更多概念和命令) | 更平缓(相对简单直接) |
| 流行程度 | 主流(特别是开源社区) | 一些传统企业仍在用 |
| 适用场景 | 分布式团队协作,现代开发流程,大小项目版本控制 | 严格中心化控制,一些老项目维护 |
优先选择 Git 的原因:
- 需要频繁离线工作(远程办公、差旅)
- 团队协作需要强大的分支和合并能力(如GitFlow工作流)
- 参与开源项目(几乎所有开源项目都在GitHub/GitLab上)
- 希望版本控制流程快速高效
- 团队规模较大或分布在不同地点
仍然选择 SVN 的原因:
- 遗留项目迁移成本过高(技术债沉重)
- 管理海量二进制资产(如游戏设计资源)
- 团队对SVN有深厚经验且工作流稳定
- 部分传统企业环境(如Windows平台特定工具链集成)
总结:优先选择 Git
四、Git 常用命令
请移步文章 Git 常用命令总结
五、Window Git Bash 常用配置
请移步文章 Window Git Bash 常用配置
常见问题
1. git 为什么需要有 index 和 repository?有什么区别
精准控制提交内容,通过 git add 可以精确的控制哪些文件的修改需要进行控制,
当然你也可以运行 git commit -a时,Git 自动将所有已跟踪文件的修改加入索引再提交,相当于隐式使用索引。但新增文件仍需显式 git add。
2. git stash 和 git commit 有什么区别?适用场景?
| - | 说明 | 保存 | 局限性 | 适用场景 |
|---|---|---|---|---|
| git commit | 提交修改到本地仓库,产生历史记录,git log 可查看 | 提交已 git add修改 |
只存在当前分支 | 日常开发 |
| git stash | 临时保存现场(存在栈中) ⚠️⚠️⚠️:git stash 是持久的,关机仍旧存在 |
新文件未 git add的无法保存,需要添加 -u 参数 | 全局,即使切换分支也能看到 stash的记录 | 开发过程中需要临时切换分支修复bug时,可以先临时 stash 保存一下 |
总结:建议大家尽可能使用 git commit,而不是用 git stash
为什么不推荐 git stash ? git commit 只有有 git log,而且使用 git reflog 可以操作记录回滚,
而你要是一不小心执行了 git stash clear,那么就真的是全世界都干净了(基本上无救)
git stash 有个最大的优势就是不会污染历史提交记录,但是在开发分支中,谁还关心 log 乱呢
3. Git 的文件颜色都有哪些?代表含义是什么?
以下是默认的颜色表示
- 红色:未加入,无版本控制
- 绿色:已加入,有版本控制,未提交
- 白色:已加入,已提交,无改动
- 蓝色:已加入,已提交,有改动
- 灰色:版本控制忽略文件
原文地址
一文带你彻底学会 Git 代码管理