- 预处理器 cpp
- C编译器 gcc
- 编译优化等级 -OX
- -O0:不优化
- -O2:默认级别
- -O3:展开循环、更多内联,有时反而变慢或行为不符预期
- -Os:空间优化(适合嵌入式):牺牲少量速度,换取更小代码段
- -Og:调试优化:保留调试信息并做少量优化,比 -O0 稍快
- 编译优化等级 -OX
- C++ 编译器 g++
- 汇编器 as
- 链接器 ld
- 二进制工具集
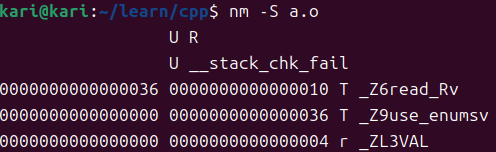
- 符号显示器 nm
- nm -S a.o # 查看符号大小和段信息
![image]()
U:未定义 T:非静态代码段 r:静态只读数据段
- nm -S a.o # 查看符号大小和段信息
- 信息查看器 objdump
- objdump -s 文件名 # 查看可执行程序数据段内容
- objdump -t a.o # 查看符号表
- 段剪辑器 objcopy:裁剪去除elf格式
- readelf -S a.o # 查看段表
- size a.o # 查看代码段/数据段/未初始化数据段大小
- 符号显示器 nm

—————补充知识点————

——————————————
编译过程:
- gcc -E -o main.i main.c
- gcc -S -o main.S main.i
- gcc -c -o main.o main.S
- gcc -o main_elf main.o
——————————————