为优化Air780EGH的UART串口性能,硬件设计需严格遵循特定规范。本文将系统梳理UART电路设计的最佳实践,包括电平配置、波特率选择、流控信号连接等关键步骤,助力开发者构建稳定且兼容的串口通信系统。
本文主要从硬件设计的角度,分享串口设计中的一些关键注意点,软件开发方面不做深入探讨。
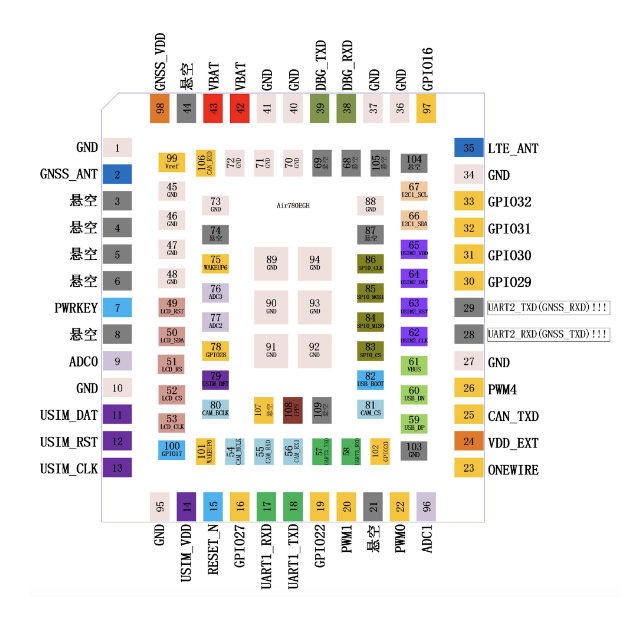
一、串口相关管脚
Air780EGH支持3个串口,分别是:
主串口UART1
扩展串口UART3
调试串口UART0
Air780EGH不支持AT指令操作,UART1/UART3仅用于LuatOS二次开发使用。
对应的管脚如下:
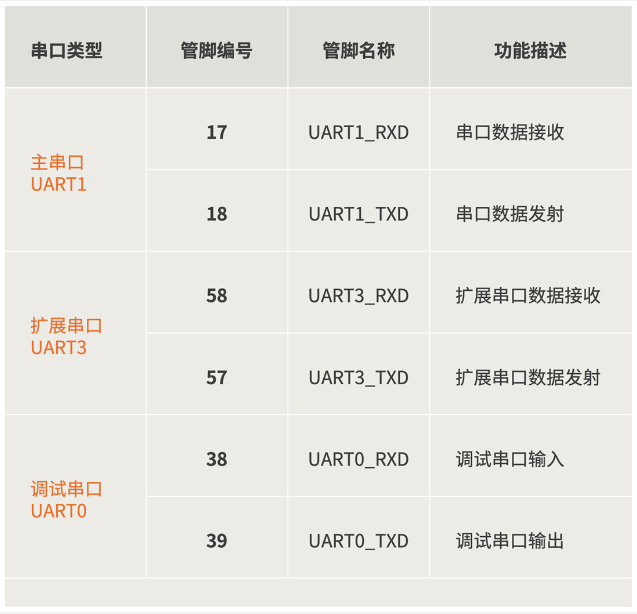
二、串口功能描述
2.1 主串口特性
模组的数据传输主要通过主串口UART1来实现,建议优先用主串口进行外部通信和模块控制。
主串口UART1有以下特性:
1)均为TTL电平串口
Air780EGH所有串口均为TTL电平串口,电平为3.0(默认)/1.8V电平。两种串口电平选择,可以通过pin100管脚配置或者二次开发代码配置。
2)只有主串口支持模组休眠唤醒功能(LPUART)
Air780EGH模组在休眠时,所有串口均为关闭状态,只有主串口支持接收串口数据唤醒模组。
注意:在非9600的其他波特率下,进行串口收发数据唤醒时,会丢失前几个字节。
3)待机状态下高电平
2.2 扩展串口
扩展串口AUX_UART从硬件上的电器特性来说,与主串口一样(但是不能支持休眠唤醒功能)。
2.3 调试串口
调试串口UART0,用来输出模块的运行日志。
调试串口固定波特率921600不可更改,不建议连接任何外设,但建议设计时预留测试点。
调试串口日志数据有专门的协议,如果用普通的串口工具抓取会显示乱码,只有用专用调试工具,如有需要请联系官方技术人员。
对于OpenCPU二次开发应用来说:
调试串口可以配置为一般串口使用,但是要注意,即使配置为一般串口在开机时软件跑起来前的这段时间内,仍然会输出调试日志,这就有可能对外接的外设造成误动作。同理,将调试串口配置为GPIO使用时也会有这个问题。
因此不是万不得已情况下,不要使用调试串口做其他功能。
三、硬件设计指导
3.1 串口的连接方式
主串口的型号命名很容易让人联想到RS232标准的DB9接口,其实不然,模组的串口连接方式与标准RS232连接方式有所不同。
标准RS232串口连接方式如下图所示,特点是交叉连接。

而模组串口遵循的是早期贺氏(HAYES)公司制定的MODEM串口标准,在这个标准下,DTR/DSR/CTS/RTS信号的功能有所不同。
MODEM串口标准标准下,DTR/DSR/CTS/RTS采用的是直连方式。
如下图示:
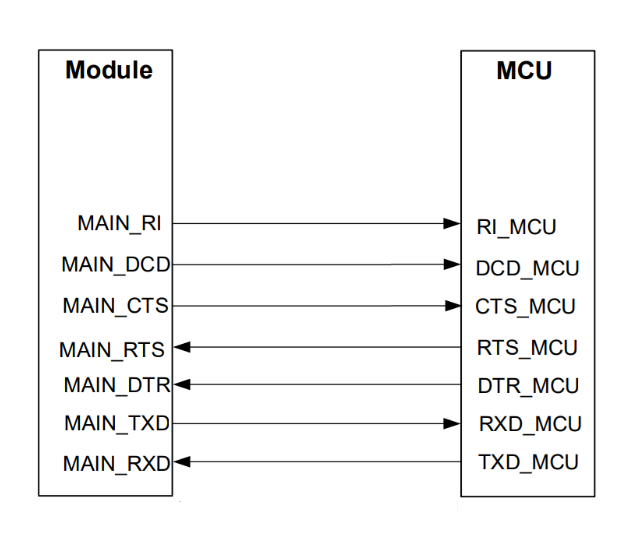
在逐渐的演变过程中,DCD/DSR/RI逐渐演变为其他的独立功能,在物联网串口应用中仅保留T/RX加流控管脚的5线串口的形式。
但是CTS/RTS的命名规则保留了下来,虽然CTS/RTS采用直连的方式,但是实际上模组的CTS管脚起到的功能是标准RTS功能;模组RTS管脚起到的功能是标准CTS功能。
连接方式如下:

甚至流控管脚也不是必须,就变成了3线串口:

3.2 串口的电平转换
Air780EGH的串口是TTL电平串口,TTL电平串口会有输入输出判别门限,如下图:

同时,外接MCU或者外设的TTL电平串口同样有判别门限。
一般来说,TTL电平的判别门限高低取决于IO供电电平VDD的高低。如果串口双方的判别门限差别较大,一方的输出高电平落在对方的高电平判别门限下,就容易出现误判的现象。
虽说Air780EGH可以通过pm.iovol() 来配置串口电平,但也仅有1.8V和3.3V两个档位,无法覆盖全部情况。
在串口双方电平不一致的情况,就要增加电平转换电路来转换通信电平。
1)双方模组串口电平差别不大的情况
例如,模组串口电平3.3V,MCU串口电平3.0V。按照上图判别门限,模组的输入高判别门限为:0.7x3.3=2.31V。
所以MCU串口高电平输出为3V,高于模组的输入高判别门限,能够稳定判断。这种情况下即使MCU与模组的电平不一致,直接连接也不会造成通信问题。
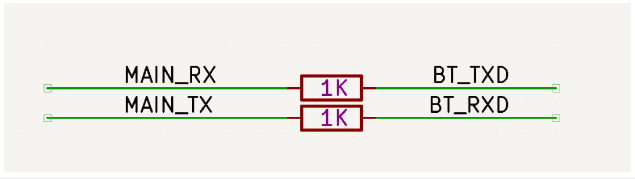
通常这种情况下,无需电平转换,只需要在串口TX/RX信号线上串联限流电阻即可。
限流电阻用于减小串口电平不匹配造成的漏电,通常按经验串联1K电阻即可,注意串联电阻不宜过大,会影响串口信号的上升下降时间,从而影响串口信号质量。
需要特别注意:
不要只看判别门限,还要考虑串口的耐压,即使落在判别门限内,但是一方高电平高于对方的IO耐压值的情况下就不能要串联电阻的方式,还是老老实实加串口电平转换。
一般来说,双方的电平差不宜超过0.5V。
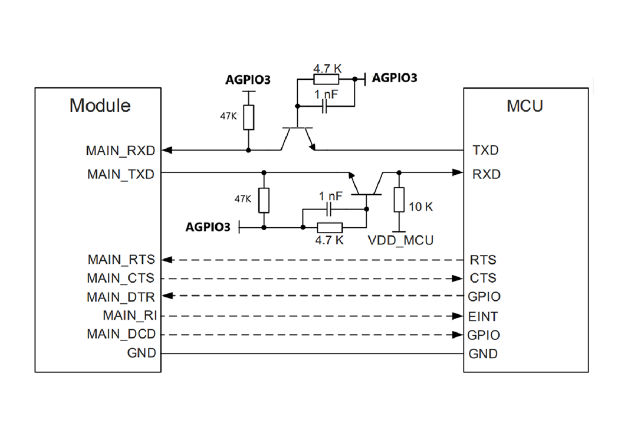
2)晶体管的电平转方案
在串口波特率不高的情况下(如115200),可以通过NPN晶体管的方式进行电平转换。
优点:成本低;
劣势:低电平下会被三极管的饱和管压降抬高(通常在0.1V左右,不影响通信);开关速度不够,超过460800波特率时不建议用这种方式。
参考设计及注意事项如下:

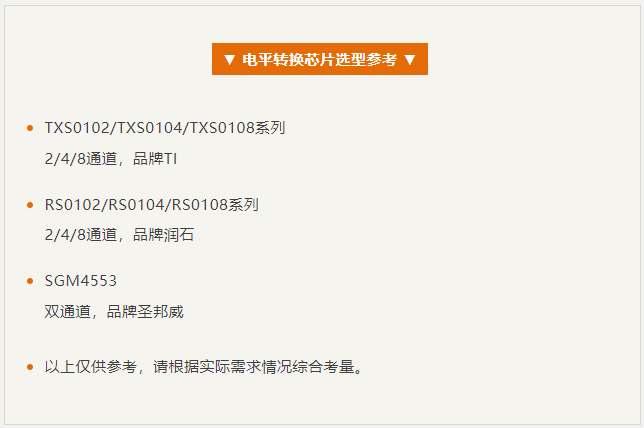
3)电平转换芯片方案
对成本不敏感的话,优先考虑用电平转换芯片,无论速度,可靠性都很完美。
对于设计方面只要注意芯片选型,同时模组端参考电平注意用AGPIO3,其他的参考具体芯片参考设计即可,没有太多注意事项。

考虑到电平转换芯片价格与通道数量成正相关,也可以采用TX/RX用双通道电平转换芯片,其他流控信号用晶体管或者分压方式来做电平转换,兼顾性能和成本。
今天的内容就分享到这里了~