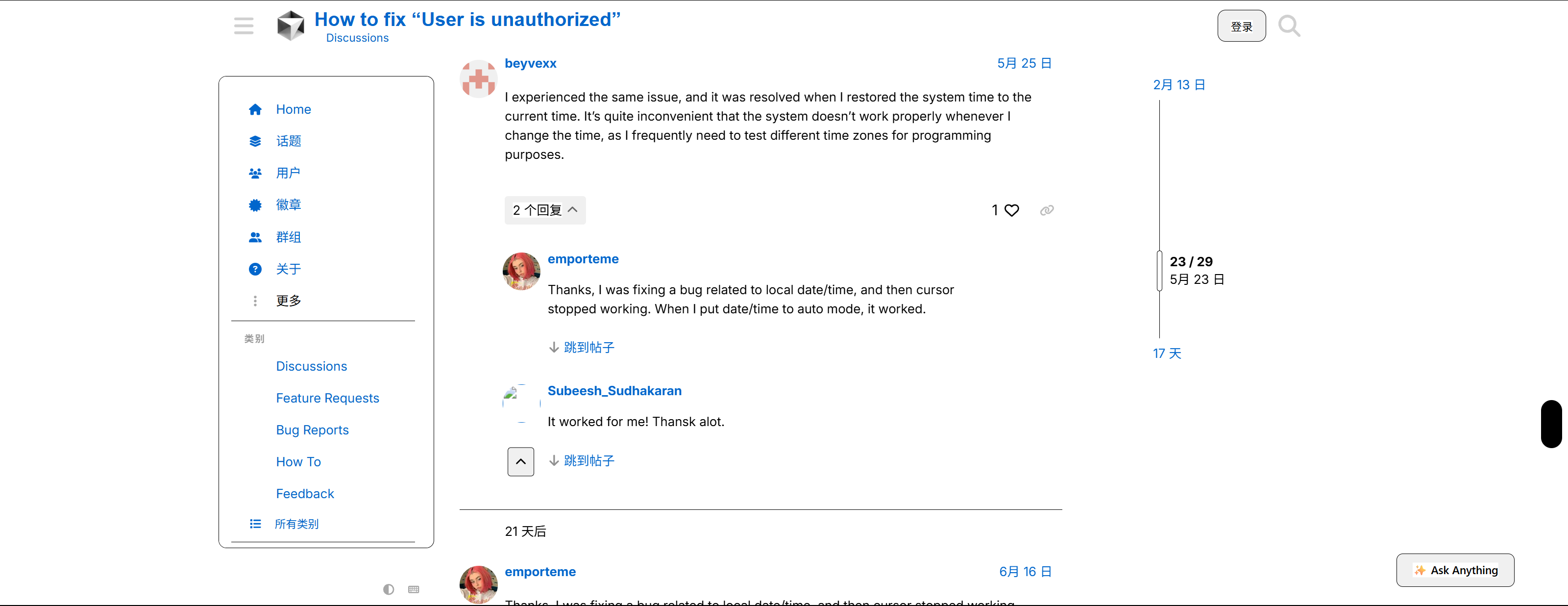
当前位置: 首页 > news >正文 事倍功半是蠢蛋39 cursor 报错user is unauthorized news 2026/1/22 10:55:26 解决方案是因为我电脑纽扣电池没电了 系统时间不对。 https://forum.cursor.com/t/how-to-fix-user-is-unauthorized/50494/23 查看全文 http://www.aitangshan.cn/news/4.html 相关文章: 一个不错的AI写作工具 2025CSP-S模拟赛33 比赛总结