前言
当你在浏览器的地址栏输入一串链接(如https://blog.dawnkylin.online)并按下回车后,一个网页就呈现在你眼前。这个过程通常不会花费太多时间,以至于我们已经习以为常。但其实幕后发生了非常多有趣的事,环环相扣之下,一切才得以成功运行。
那么,从链接的概念开始来了解其中的来龙去脉。链接是打开互联网大门的钥匙🔑,专业人士称其为 URL。
旅程目的地:URL
URL 是 Uniform Resource Locator 的缩写,意为统一资源定位符。它是互联网上唯一资源的地址,告诉了浏览器去何处取得资源。
URL 是 URI(Uniform Resource Identifier,统一资源标识符)的子集,一种特殊类型的 URI,许多人经常将它两混为一谈。此外,URI 还包括 URN(Uniform Resource Name,标识资源的名称或身份但不能定位),如urn:isbn:0451450523标识了一本书。
下面来看看 URL 的格式。

(1)scheme是通信协议,它表示以哪种服务方式来传输信息,例如,http是普通传输,https是加密传输,mailto是邮件方式,ftp是文件传输,file是访问本地文件(如访问一个本地 pdf 文件:file:///C://Users/xxx/Documents/xxx.pdf)。
(2)authority这个可选部分由用户信息(包括用户名和可选的密码)、主机名(host)、端口(port)三部分组成。明文提供用户信息会造成安全问题,所以一般是不用的;主机名表示资源所在的服务器,可以是域名(如www.example.com)或 IP 地址(如 IPv4 地址:192.0.2.1或 IPv6 地址:[2001:db8::1]),域名对人类友好、易记,可以指向多个 IP 地址,一个 IP 地址通常对应一台服务器,但也可以通过负载均衡映射多台服务器(如通过 Nginx 实现);端口是操作系统用来区分不同网络服务的“门牌号”,每个 IP 地址最多可以有 65536 个端口(0~65535),有些端口是某些协议的默认端口。
大多数情况下,普通用户只需要记住通信协议、主机名、端口就能正常访问一个网站了,甚至通信协议和端口都可以忽略。因为现代浏览器会自动补全使用
HTTPS,如果你只输入example.com,浏览器会尝试https://example.com。而对于端口号,HTTP 默认是 80,HTTPS 默认是 443。只要网站使用默认端口,用户就不需要手动输入,如果你硬要加上,浏览器也会将它抹除。
(3)path是 Web 服务器上资源的路径,早期它是物理路径,现如今它由服务器程序动态处理生成,并不一定指向真实文件路径。
(4)query提供了给 Web 服务器的额外查询参数,例如?id=123&lang=zh,这个部分一般无需用户操心。
(5)fragment是片段标识符或锚点(anchor),相当于书中的标签。这部分不会被发送到服务器,浏览器会自动滚动到对应的锚点(如<a name="section2">或有id="section2"的元素)。
浏览器把我们输入的链接按照上面几部分解析好后,就要开始发起请求了,很明显请求目标是主机名对应的服务器,且一般来说我们使用域名作为主机名,这时候就需要在开始建立连接前查询该域名对应的 IP 地址,因为网络通信使用的是 IP 地址。这就像电话薄一样,光有人名打不通电话,还得有他的手机号码。即使域名和 IP 地址一样具有唯一性,但域名 -> IP这个组合仍不建议被拆散或单独使用,因为域名更人性化、更适合推广,而 IP 地址可变性强,可以随时更换,给了域名更多的“自由”。
查询域名对应的 IP 是结合域名系统(Domain Name System, DNS)完成的。
域名查询机制
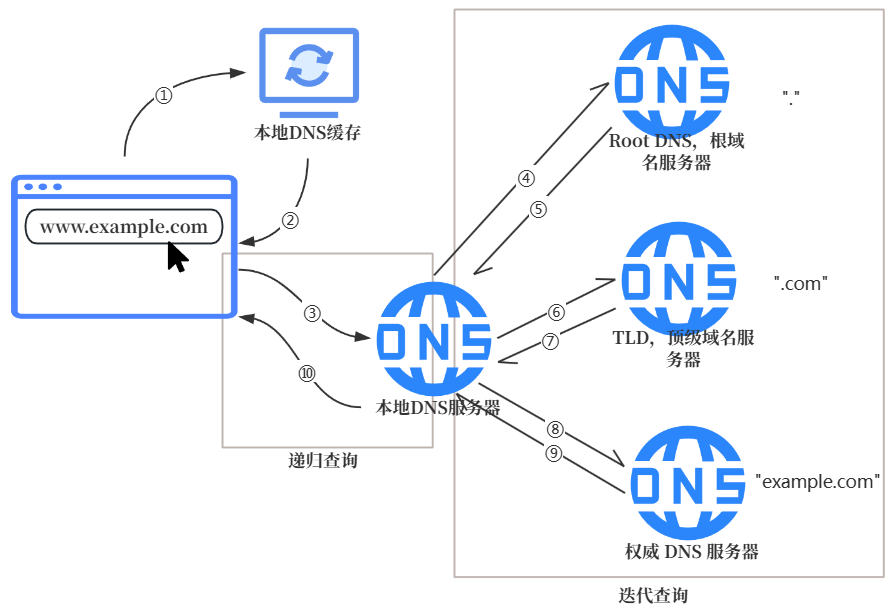
浏览器会先询问本地操作系统有没有缓存的 IP 地址(Windows 系统在 CMD 中输入ipconfig /displaydns就能查看 DNS 缓存),有就直接返回该 IP,如果没有,就会发起 DNS 请求给本地网络 DNS 服务器(通常由运营商或路由器指定),若也没有,则由本地 DNS 作为中间人,逐层查询根域名服务器、顶级域名服务器和权威域名服务器,直到找到对应 IP 地址。
域名并不是一个整体,它是分级结构。以www.example.com为例,从右到左,域名层级递减,它还有一个隐藏的根域.,由根域名服务器管理,当本地 DNS 服务器无法解析域名时,就会告诉它去哪个 TLD 查询.com。.com为顶级域,由 TLD 管理,TLD 会告诉你example.com的权威 DNS 服务器地址。example.com为二级域名,是网站注册的域名,www.example.com为其子域名,由权威 DNS 服务器返回子域名 IP 地址。
递归查询是指一次查询就能返回结果;迭代查询,就是从查询响应结果中获得下一次查询的服务器地址。
浏览器拿到服务器 IP 地址后该如何用它呢?想想我们写信的过程,写好信后,放在信封里,并填好寄送地址与收件人。网络通信也是同理,只不过这封“信”会经过多层信封包装。这就涉及到了网络世界的一个重要概念:网络分层模型。
网络分层模型
网络分层模型是理解现代通信协议的基础,它就像一座“协议大厦”,每一层都有自己的职责、协议和数据结构。最经典的模型有两个:
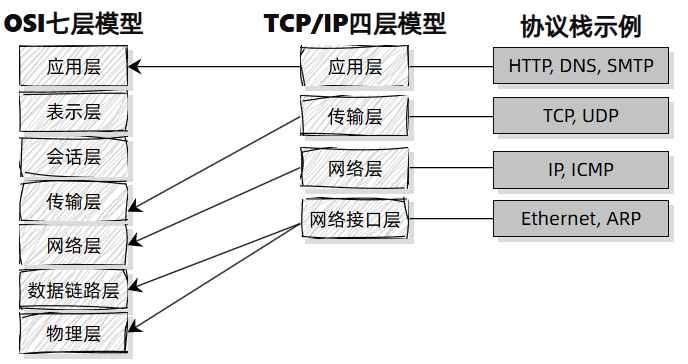
OSI 七层模型是理论标准模型,TCP/IP 四层模型是实用模型。还有一个非常常用的五层网络模型,它是介于理论和实践之间的“教学版”模型,尤其在大学课程和技术培训中非常常见,它在 TCP/IP 四层模型的基础上将网络接口层换成数据链路层和物理层。
在发送方,数据会从上至下依次“加工”封装:
- 应用层生成数据(如网页请求)
- 传输层加上端口号、序列号
- 网络层加上 IP 地址
- 链路层加上 MAC 地址
- 物理层转成电信号或无线信号发送出去
接收方则反向解封装,一层层还原数据。
IP 地址和 MAC 地址该如何理解?它们在作用上又有何差异?
MAC 地址是烧录在设备上的不可变的全球唯一识别码,主要作用是用于局域网(LAN)内的点到点通信。咱们家里的 Wi-Fi 网络就是一个典型的局域网,路由器把你所有设备连接起来,可以在内部直接通信(比如手机和打印机之间互传文件),不需要“出门”访问互联网,点到点通信也正是这个意思。
IP 地址表示你在哪一个网络,如果目标 IP 地址与局域网不属于一个网络,那么数据就需要从局域网传到另一个网络,这就进入了 IP 地址的主场:此时设备之间的通信就是端到端通信,靠的是 IP 地址来完成定位和传输。直到找到了与目标 IP 地址属于相同网络的局域网,就通过 ARP 协议查询该 IP 地址在该局域网内对应的设备 MAC 地址。
到了这里,数据报文已经可以成功封装,可以开始与目标服务器建立通信连接了。
与目标服务器建立连接
既然大家连着网,为啥还要建立啥子连接呀?
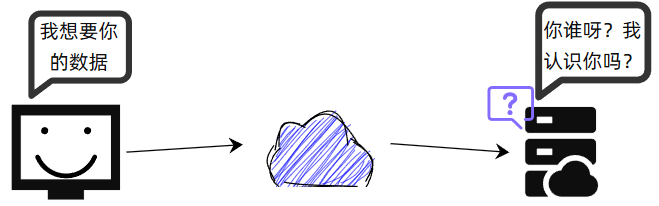
这就像千方百计拿到了一个人的电话,没有提前打招呼啥的,拨打过去就是提要求,对面自然是怀疑、感觉莫名其妙了。正常的有礼貌的电话问候流程应该是:
- 你拨号📞
- 对方接听并说“你好啊!”🙂
- 你回应“你好你好,我能听见!”😀
因此一个正常的建立连接的过程如下图:
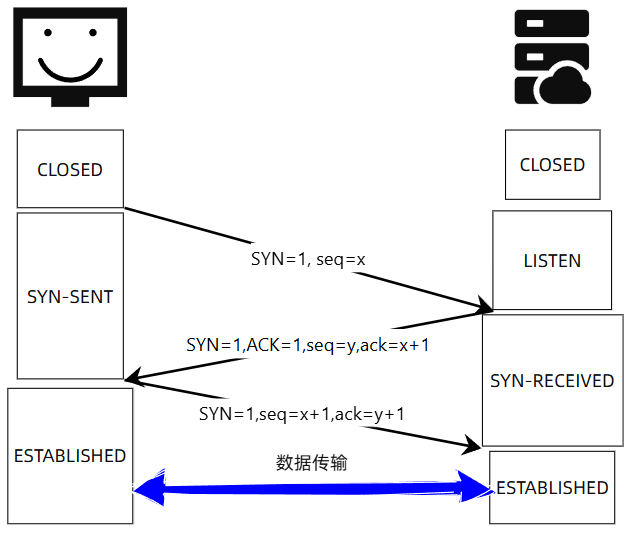
TCP 是确保通信可靠的协议,其约定在通信前必须建立连接。上图中“三次握手”就是为了确认彼此的存在、能力和状态。
第一次握手,客户端发送一个 SYN(同步) 报文,表示“我想建立连接,并告诉你我的初始序列号(Sequence Number)”,客户端状态变为SYN-SENT;第二次握手,服务器收到 SYN 后,回复一个 SYN + ACK 报文,同时发送自己的初始序列号,表示“我愿意建立连接,并已确认你的序列号”,服务器状态变为SYN-RECEIVED;第三次握手,客户端收到服务器的 SYN + ACK 后,发送一个 ACK 报文,表示“我确认了你的序列号”,客户端状态变为ESTABLISHED,服务器收到后状态也变成ESTABLISHED,连接建立完毕,开始数据传输(其实一般还有 TLS 握手过程,建立加密通道)。
请求及响应
浏览器构造并发送请求报文,例如:
GET / HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/116.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
服务器返回响应:
HTTP/1.1 200 OK
Date: Mon, 11 Aug 2025 15:32:00 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: gzip
Content-Length: 1024
Cache-Control: max-age=3600
Server: Apache<!DOCTYPE html>
<html>
<head>...
</head>
<body>...
</body>
</html>
响应报文中空行下方就是我们的网页的真实样貌与结构。它是使用超文本标记语言 HTML 编写的,是网页的“骨架”,其中可能还包含样式语言 CSS 和逻辑交互语言 JavaScript,浏览器就会根据它们来渲染出一个功能完备的网页!🎉
阅读原文