目录
- 对射式红外传感器记次
- 接线图
- 代码实现
- 标准库实现
- CountSensor.h
- CountSensor.c
- main.c
- HAL库实现
- IDE配置
- 代码实现
- CountSensor.h
- CountSensor.c
- stm32f1xx_it.c
- main.c
- 标准库实现
- 实现效果
对射式红外传感器记次
利用外部中断实现上述功能,外部中断适合突发的信号,用脉冲过来,stm32立即处理,没有脉冲的适合,stm32就专心做其他事情,红外接收器也用外部中断,但是按键不适合用外部中断,因为外部中断不好处理按键抖动和松手检测的问题
接线图

代码实现
打开中断,就是把这些电路打开

标准库实现
已开源到https://gitee.com/qin-ruiqian/jiangkeda-stm32
CountSensor.h
#ifndef __COUNTSENSOR_H__
#define __COUNTSENSOR_H__void CountSensor_Init(void); //初始化对射式红外传感器记次
uint16_t CountSensor_Get(void); //返回传感器次数#endifCountSensor.c
#include "stm32f10x.h" // Device header//记录传感器的遮挡次数
uint16_t CountSensor_Count;//初始化对射式红外传感器记次
void CountSensor_Init(void)
{RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOB, ENABLE);RCC_APB2PeriphClockCmd(RCC_APB2Periph_AFIO, ENABLE);GPIO_InitTypeDef GPIO_InitSturcture;GPIO_InitSturcture.GPIO_Mode = GPIO_Mode_IPU; //上拉输入,EXTI要求浮空上拉或者下拉GPIO_InitSturcture.GPIO_Pin = GPIO_Pin_14;GPIO_InitSturcture.GPIO_Speed = GPIO_Speed_50MHz;GPIO_Init(GPIOB, &GPIO_InitSturcture);//配置AFIO,选择中断的外部寄存器和引脚GPIO_EXTILineConfig(GPIO_PortSourceGPIOB, GPIO_PinSource14);//配置EXTIEXTI_InitTypeDef EXTI_InitStructure;EXTI_InitStructure.EXTI_Line = EXTI_Line14; //指定配置的中断线EXTI_InitStructure.EXTI_LineCmd = ENABLE; //开启中断EXTI_InitStructure.EXTI_Mode = EXTI_Mode_Interrupt; //选择中断模式,而不是事件模式EXTI_Mode_EventEXTI_InitStructure.EXTI_Trigger = EXTI_Trigger_Falling; //下降沿触发,移开挡光片的时候触发EXTI_Init(&EXTI_InitStructure);//配置NVIC//配置优先级分组,抢占优先级和响应优先级//只有一个中断的话,分的比较平均一些//2位抢占,2位响应//要确保每个模块分组配置都是同一个,如果不放心可放在主函数中//我就放在这里了NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);NVIC_InitTypeDef NVIC_InitStructure;NVIC_InitStructure.NVIC_IRQChannel = EXTI15_10_IRQn; //选择15-10的合并的通道NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE; //指定中断通道使能NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 1; //分组2,2位抢占,0-3NVIC_InitStructure.NVIC_IRQChannelSubPriority = 1; //这里是响应优先级,都是2位二进制,都设置为1NVIC_Init(&NVIC_InitStructure);
}//返回传感器次数
uint16_t CountSensor_Get(void)
{return CountSensor_Count;
}//处理15-10中断线的中断,中断函数不需要在头文件声明
//中断函数自动执行
void EXTI15_10_IRQHandler(void)
{//15-10集成到一根线//所以要判断一下EXTI14的标志位是不是为1//如果是,执行第14个线的中断程序if(EXTI_GetITStatus(EXTI_Line14) == SET){CountSensor_Count++; //传感器次数自增//每次中断程序结束后,都应该清除一下中断标志位//否则程序就一直卡在这里EXTI_ClearITPendingBit(EXTI_Line14);}
}main.c
#include "stm32f10x.h" // Device header
#include "Delay.h"
#include "MYOLED.h"
#include "CountSensor.h"int main(void)
{MYOLED_Init();CountSensor_Init();MYOLED_ShowString(0,0, "Count:");while(1){MYOLED_ShowNum(6, 0, CountSensor_Get(), 5);}
}HAL库实现
IDE配置
先设置14引脚是外部中断14
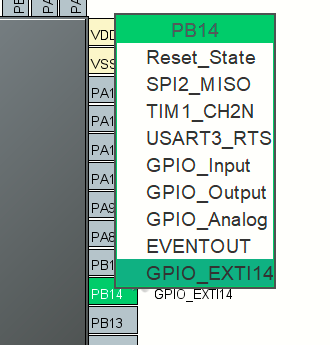
选择14号引脚下降沿触发(和标准库那个实现保持一致)
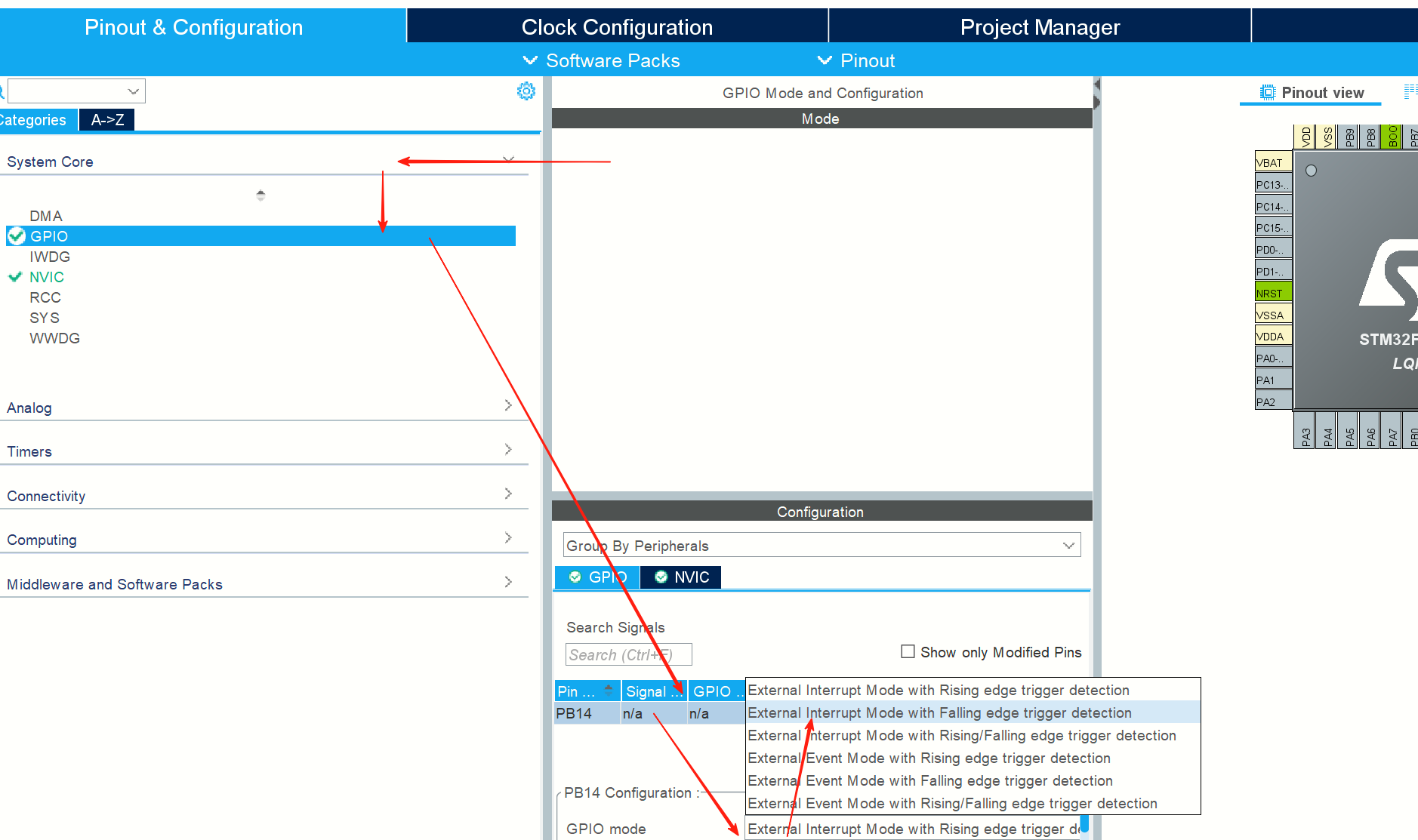
下面设置浮空还是上拉下拉的选项不用选,默认浮空输出
然后设置NVIC,2分组,10-15允许中断,如果出现2分组报错,可能是某个中断抢占式优先级或者响应优先级没有按照2分组分配好(0-3范围),其余和标准库版本配置一致:
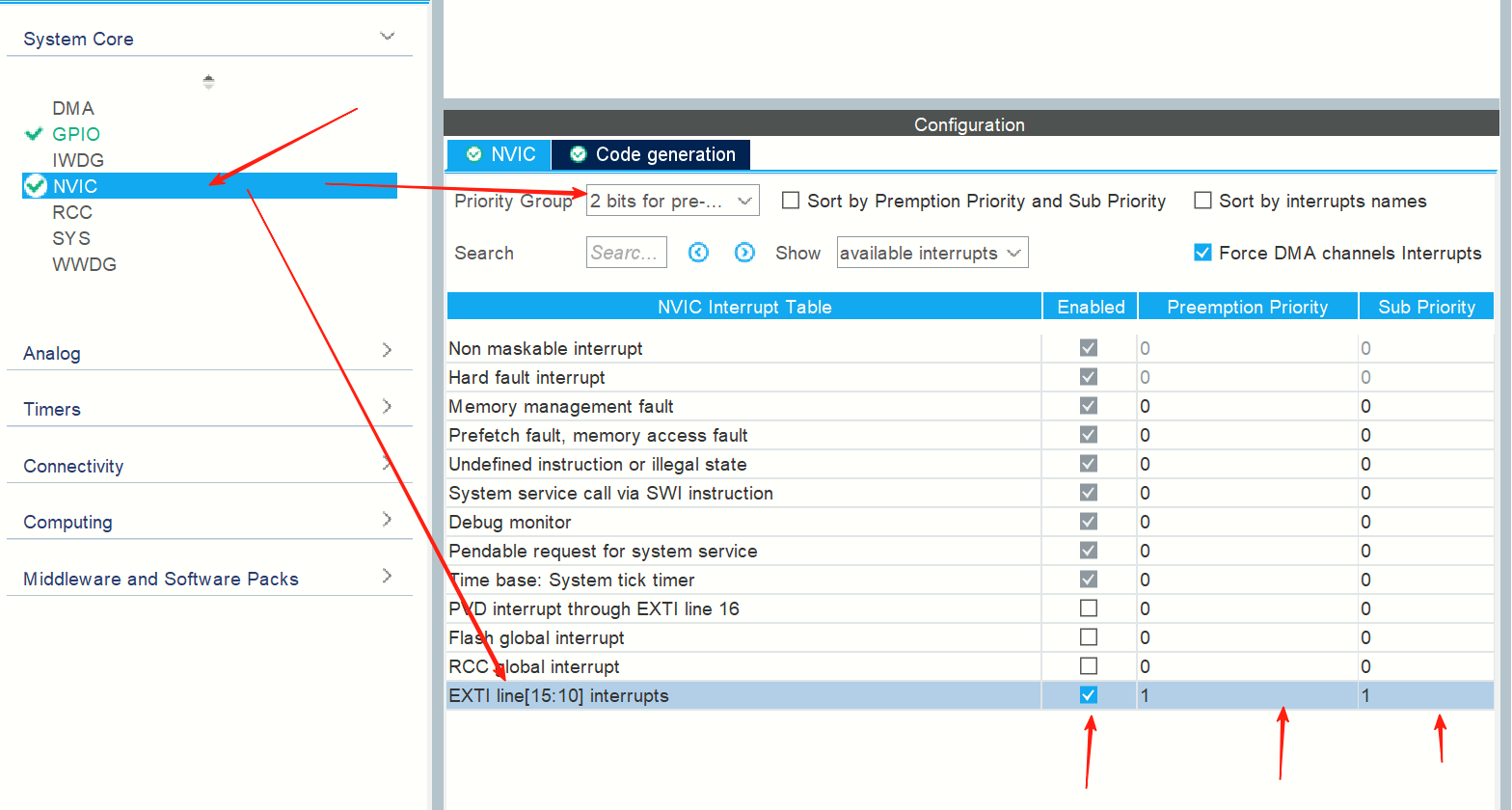
中断的内容在自动生成的项目初始代码的这个源文件中:
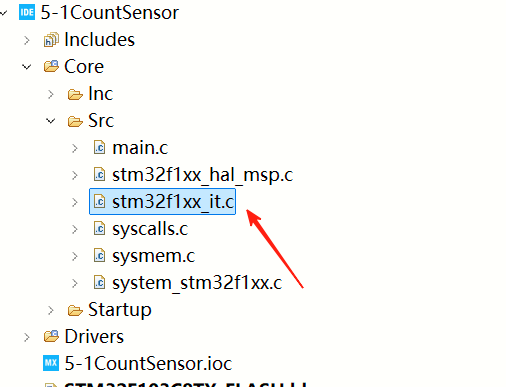
然后找到这里添加中断的逻辑
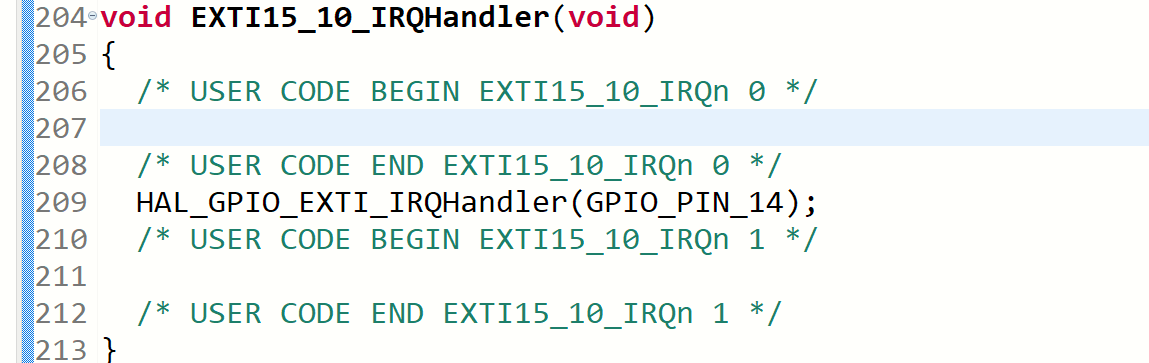
这里添加一个判断,判断14号引脚是否发生中断
以后中断的逻辑都写在这个源文件中,然后把计数器逻辑单独写一份放到hardware目录里,然后再设置一下编译器读取头文件路径和编译器生成16进制文件等,不再赘述,可参考我这系列之前的文章
最重要的是别忘了给PB8 PB9端口设置开漏输出默认高电平,要不然OLED屏幕没有反应(可参考:https://www.cnblogs.com/qinruiqian/p/19029931)
代码实现
已开源到:https://gitee.com/qin-ruiqian/jiangkeda-stm32-hal
CountSensor.h
/** CountSensor.h** Created on: Aug 11, 2025* Author: Administrator*/#ifndef HARDWARE_COUNTSENSOR_H_
#define HARDWARE_COUNTSENSOR_H_uint16_t CountSensor_Get(void); //返回传感器次数
void CountSensor_Add(void); //传感器计数器加1#endif /* HARDWARE_COUNTSENSOR_H_ */CountSensor.c
/** CountSensor.c** Created on: Aug 11, 2025* Author: Administrator*/
#include "stm32f1xx_hal.h"//记录传感器的遮挡次数
uint16_t CountSensor_Count;//返回传感器次数
uint16_t CountSensor_Get(void)
{return CountSensor_Count;
}//传感器计数器加1
void CountSensor_Add(void)
{CountSensor_Count++;
}stm32f1xx_it.c
/* USER CODE BEGIN Header */
/********************************************************************************* @file stm32f1xx_it.c* @brief Interrupt Service Routines.******************************************************************************* @attention** Copyright (c) 2025 STMicroelectronics.* All rights reserved.** This software is licensed under terms that can be found in the LICENSE file* in the root directory of this software component.* If no LICENSE file comes with this software, it is provided AS-IS.********************************************************************************/
/* USER CODE END Header *//* Includes ------------------------------------------------------------------*/
#include "main.h"
#include "stm32f1xx_it.h"
/* Private includes ----------------------------------------------------------*/
/* USER CODE BEGIN Includes */
#include "CountSensor.h"
/* USER CODE END Includes *//* Private typedef -----------------------------------------------------------*/
/* USER CODE BEGIN TD *//* USER CODE END TD *//* Private define ------------------------------------------------------------*/
/* USER CODE BEGIN PD *//* USER CODE END PD *//* Private macro -------------------------------------------------------------*/
/* USER CODE BEGIN PM *//* USER CODE END PM *//* Private variables ---------------------------------------------------------*/
/* USER CODE BEGIN PV *//* USER CODE END PV *//* Private function prototypes -----------------------------------------------*/
/* USER CODE BEGIN PFP *//* USER CODE END PFP *//* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 *//* USER CODE END 0 *//* External variables --------------------------------------------------------*//* USER CODE BEGIN EV *//* USER CODE END EV *//******************************************************************************/
/* Cortex-M3 Processor Interruption and Exception Handlers */
/******************************************************************************/
/*** @brief This function handles Non maskable interrupt.*/
void NMI_Handler(void)
{/* USER CODE BEGIN NonMaskableInt_IRQn 0 *//* USER CODE END NonMaskableInt_IRQn 0 *//* USER CODE BEGIN NonMaskableInt_IRQn 1 */while (1){}/* USER CODE END NonMaskableInt_IRQn 1 */
}/*** @brief This function handles Hard fault interrupt.*/
void HardFault_Handler(void)
{/* USER CODE BEGIN HardFault_IRQn 0 *//* USER CODE END HardFault_IRQn 0 */while (1){/* USER CODE BEGIN W1_HardFault_IRQn 0 *//* USER CODE END W1_HardFault_IRQn 0 */}
}/*** @brief This function handles Memory management fault.*/
void MemManage_Handler(void)
{/* USER CODE BEGIN MemoryManagement_IRQn 0 *//* USER CODE END MemoryManagement_IRQn 0 */while (1){/* USER CODE BEGIN W1_MemoryManagement_IRQn 0 *//* USER CODE END W1_MemoryManagement_IRQn 0 */}
}/*** @brief This function handles Prefetch fault, memory access fault.*/
void BusFault_Handler(void)
{/* USER CODE BEGIN BusFault_IRQn 0 *//* USER CODE END BusFault_IRQn 0 */while (1){/* USER CODE BEGIN W1_BusFault_IRQn 0 *//* USER CODE END W1_BusFault_IRQn 0 */}
}/*** @brief This function handles Undefined instruction or illegal state.*/
void UsageFault_Handler(void)
{/* USER CODE BEGIN UsageFault_IRQn 0 *//* USER CODE END UsageFault_IRQn 0 */while (1){/* USER CODE BEGIN W1_UsageFault_IRQn 0 *//* USER CODE END W1_UsageFault_IRQn 0 */}
}/*** @brief This function handles System service call via SWI instruction.*/
void SVC_Handler(void)
{/* USER CODE BEGIN SVCall_IRQn 0 *//* USER CODE END SVCall_IRQn 0 *//* USER CODE BEGIN SVCall_IRQn 1 *//* USER CODE END SVCall_IRQn 1 */
}/*** @brief This function handles Debug monitor.*/
void DebugMon_Handler(void)
{/* USER CODE BEGIN DebugMonitor_IRQn 0 *//* USER CODE END DebugMonitor_IRQn 0 *//* USER CODE BEGIN DebugMonitor_IRQn 1 *//* USER CODE END DebugMonitor_IRQn 1 */
}/*** @brief This function handles Pendable request for system service.*/
void PendSV_Handler(void)
{/* USER CODE BEGIN PendSV_IRQn 0 *//* USER CODE END PendSV_IRQn 0 *//* USER CODE BEGIN PendSV_IRQn 1 *//* USER CODE END PendSV_IRQn 1 */
}/*** @brief This function handles System tick timer.*/
void SysTick_Handler(void)
{/* USER CODE BEGIN SysTick_IRQn 0 *//* USER CODE END SysTick_IRQn 0 */HAL_IncTick();/* USER CODE BEGIN SysTick_IRQn 1 *//* USER CODE END SysTick_IRQn 1 */
}/******************************************************************************/
/* STM32F1xx Peripheral Interrupt Handlers */
/* Add here the Interrupt Handlers for the used peripherals. */
/* For the available peripheral interrupt handler names, */
/* please refer to the startup file (startup_stm32f1xx.s). */
/******************************************************************************//*** @brief This function handles EXTI line[15:10] interrupts.*/
void EXTI15_10_IRQHandler(void)
{/* USER CODE BEGIN EXTI15_10_IRQn 0 */if(__HAL_GPIO_EXTI_GET_FLAG(GPIO_PIN_14)){CountSensor_Add(); //计数器自增1/* USER CODE END EXTI15_10_IRQn 0 */HAL_GPIO_EXTI_IRQHandler(GPIO_PIN_14); //自动清除中断标志位/* USER CODE BEGIN EXTI15_10_IRQn 1 */}/* USER CODE END EXTI15_10_IRQn 1 */
}/* USER CODE BEGIN 1 *//* USER CODE END 1 */main.c
/* USER CODE BEGIN Header */
/********************************************************************************* @file : main.c* @brief : Main program body******************************************************************************* @attention** Copyright (c) 2025 STMicroelectronics.* All rights reserved.** This software is licensed under terms that can be found in the LICENSE file* in the root directory of this software component.* If no LICENSE file comes with this software, it is provided AS-IS.********************************************************************************/
/* USER CODE END Header */
/* Includes ------------------------------------------------------------------*/
#include "main.h"/* Private includes ----------------------------------------------------------*/
/* USER CODE BEGIN Includes */
#include "MYOLED.h"
#include "CountSensor.h"
/* USER CODE END Includes *//* Private typedef -----------------------------------------------------------*/
/* USER CODE BEGIN PTD *//* USER CODE END PTD *//* Private define ------------------------------------------------------------*/
/* USER CODE BEGIN PD *//* USER CODE END PD *//* Private macro -------------------------------------------------------------*/
/* USER CODE BEGIN PM *//* USER CODE END PM *//* Private variables ---------------------------------------------------------*//* USER CODE BEGIN PV *//* USER CODE END PV *//* Private function prototypes -----------------------------------------------*/
void SystemClock_Config(void);
static void MX_GPIO_Init(void);
/* USER CODE BEGIN PFP *//* USER CODE END PFP *//* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 *//* USER CODE END 0 *//*** @brief The application entry point.* @retval int*/
int main(void)
{/* USER CODE BEGIN 1 *//* USER CODE END 1 *//* MCU Configuration--------------------------------------------------------*//* Reset of all peripherals, Initializes the Flash interface and the Systick. */HAL_Init();/* USER CODE BEGIN Init *//* USER CODE END Init *//* Configure the system clock */SystemClock_Config();/* USER CODE BEGIN SysInit *//* USER CODE END SysInit *//* Initialize all configured peripherals */MX_GPIO_Init();/* USER CODE BEGIN 2 */MYOLED_Init();MYOLED_ShowString(0, 0, "Count:");//MYOLED_ShowString(0, 0, "CountA:");/* USER CODE END 2 *//* Infinite loop *//* USER CODE BEGIN WHILE */while (1){MYOLED_ShowNum(6, 0, CountSensor_Get(), 5);/* USER CODE END WHILE *//* USER CODE BEGIN 3 */}/* USER CODE END 3 */
}/*** @brief System Clock Configuration* @retval None*/
void SystemClock_Config(void)
{RCC_OscInitTypeDef RCC_OscInitStruct = {0};RCC_ClkInitTypeDef RCC_ClkInitStruct = {0};/** Initializes the RCC Oscillators according to the specified parameters* in the RCC_OscInitTypeDef structure.*/RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSI;RCC_OscInitStruct.HSIState = RCC_HSI_ON;RCC_OscInitStruct.HSICalibrationValue = RCC_HSICALIBRATION_DEFAULT;RCC_OscInitStruct.PLL.PLLState = RCC_PLL_NONE;if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK){Error_Handler();}/** Initializes the CPU, AHB and APB buses clocks*/RCC_ClkInitStruct.ClockType = RCC_CLOCKTYPE_HCLK|RCC_CLOCKTYPE_SYSCLK|RCC_CLOCKTYPE_PCLK1|RCC_CLOCKTYPE_PCLK2;RCC_ClkInitStruct.SYSCLKSource = RCC_SYSCLKSOURCE_HSI;RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1;RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV1;RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV1;if (HAL_RCC_ClockConfig(&RCC_ClkInitStruct, FLASH_LATENCY_0) != HAL_OK){Error_Handler();}
}/*** @brief GPIO Initialization Function* @param None* @retval None*/
static void MX_GPIO_Init(void)
{GPIO_InitTypeDef GPIO_InitStruct = {0};/* USER CODE BEGIN MX_GPIO_Init_1 *//* USER CODE END MX_GPIO_Init_1 *//* GPIO Ports Clock Enable */__HAL_RCC_GPIOB_CLK_ENABLE();__HAL_RCC_GPIOA_CLK_ENABLE();/*Configure GPIO pin Output Level */HAL_GPIO_WritePin(GPIOB, GPIO_PIN_8|GPIO_PIN_9, GPIO_PIN_SET);/*Configure GPIO pin : PB14 */GPIO_InitStruct.Pin = GPIO_PIN_14;GPIO_InitStruct.Mode = GPIO_MODE_IT_FALLING;GPIO_InitStruct.Pull = GPIO_NOPULL;HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);/*Configure GPIO pins : PB8 PB9 */GPIO_InitStruct.Pin = GPIO_PIN_8|GPIO_PIN_9;GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_OD;GPIO_InitStruct.Pull = GPIO_NOPULL;GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW;HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);/* EXTI interrupt init*/HAL_NVIC_SetPriority(EXTI15_10_IRQn, 1, 1);HAL_NVIC_EnableIRQ(EXTI15_10_IRQn);/* USER CODE BEGIN MX_GPIO_Init_2 *//* USER CODE END MX_GPIO_Init_2 */
}/* USER CODE BEGIN 4 *//* USER CODE END 4 *//*** @brief This function is executed in case of error occurrence.* @retval None*/
void Error_Handler(void)
{/* USER CODE BEGIN Error_Handler_Debug *//* User can add his own implementation to report the HAL error return state */__disable_irq();while (1){}/* USER CODE END Error_Handler_Debug */
}#ifdef USE_FULL_ASSERT
/*** @brief Reports the name of the source file and the source line number* where the assert_param error has occurred.* @param file: pointer to the source file name* @param line: assert_param error line source number* @retval None*/
void assert_failed(uint8_t *file, uint32_t line)
{/* USER CODE BEGIN 6 *//* User can add his own implementation to report the file name and line number,ex: printf("Wrong parameters value: file %s on line %d\r\n", file, line) *//* USER CODE END 6 */
}
#endif /* USE_FULL_ASSERT */实现效果
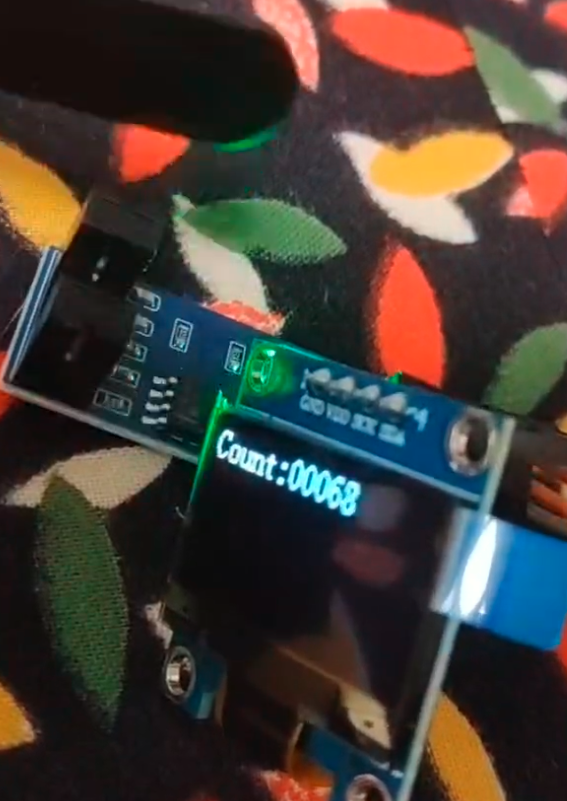
由于设置按下降沿触发,所以移开挡光片的时候触发